
ArXiv
Preprint
Source Code
Github
Dataset
and Models

Demo Colab:
Model Editing
Demo Colab:
Causal Tracing
Youtube
(Yannic Kilcher)
Where are the Facts Inside a Language Model?
Knowing differs from saying: uttering words by rote is different from knowing a fact, because knowledge of a fact generalizes across contexts. In this project, we show that factual knowledge within GPT also corresponds to a localized computation that can be directly edited. For example, we can make a small change to a small set of the weights of GPT-J to teach it the counterfactual "Eiffel Tower is located in the city of Rome." Rather than merely regurgitating the new sentence, it will generalize that specific counterfactual knowledge and apply it in very different linguistic contexts.

Why Locate Facts?
We are interested how and where a model stores its factual associations, for two reasons:
- To understand huge opaque neural networks. The internal computations of large language models are obscure. Clarifying the processing of facts is one step in understanding massive transformer networks.
- Fixing mistakes. Models are often incorrect, biased, or private, and we would like to develop methods that will enable debugging and fixing of specific factual errors.
The facts we study take the form of knowledge tuples t = (s, r, o), where s and o are subject and object entities, respectively, and r is the relation connecting the two. For example, (s = Megan Rapinoe, r = plays sport professionally, o = soccer) indicates that Rapinoe plays soccer for a living. Each variable represents an entity or relation that can be found in a knowledge graph, and that can be written as a natural language string.
To query GPT for knowledge of a fact, we express (s, r) as a text prompt (by expanding a template from the CounterFact data set), and check whether the generated continuation matches o.
What Did We Find?
In GPT-style transformer models, we discovered two things:
1. Factual associations can be localized along three dimensions, to (1) MLP module parameters (2) at a range of middle layers and (3) specifically during processing of the last token of the subject.

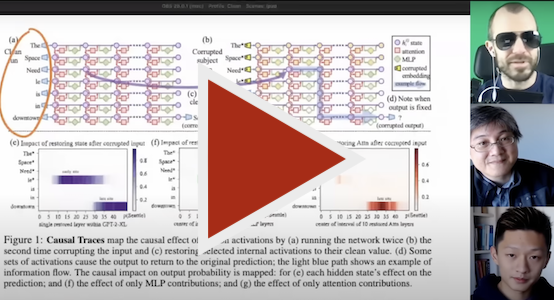
The causal trace above reveals a small number of states that contain information that can flip the model from one factual prediction to another. Our studies use such causal traces and find evidence that knowledge retrieval occurs in MLP modules at the early site (at (a) in the figure); then attention mechanisms at the late site (at (b) in the figure) bring the information to the end of the computation where the specific word can be predicted.
2. Individual factual associations can be changed by making small rank-one changes in a single MLP module. We can distinguish between changes in knowledge versus superficial changes in language by measuring generalization to other wordings of the same fact.

The example above shows that changing the model's processing of a single statement about the Eiffel Tower, if done by changing selected parameters in the right way, will result in expressing a change in knowledge in a variety of nontrivial contexts.
At (a) in in the figure, a single direct statement of a counterfactual is posed, and it is used to compute a rank-one parameter change in a single MLP module. Despite the simplicity of the change, results shown at (b) show that for a more complex prompt about travel from Berlin, the model treats the Eiffel tower as if it is in Rome; similarly in (c) when asked about nearby sites, the model suggests places in Rome before explicitly mentioning Rome. Changes in predictions in such different contexts is evidence that change generalizes: the model has not merely learned to parrot the exact sequence of words in the counterfactual, but it also applies the new knowledge in sentences that are very different from the original example.
How to Locate Factual Retrieval
To identify decisive computations, we introduce a method called Causal Tracing. By isolating the causal effect of individual states within the network while processing a factual statement, we can trace the path followed by information through the network.

Causal traces work by running a network multiple times, introducing corruptions to frustrate the computation, and then restoring individual states in order to identify the information that restores the results. Tracing can be used to test any individual state or combinations of states. We use carefully-designed traces to identify a specific small set of MLP module computations that mediate retrieval of factual associations.
Then we check this finding by asking: can the MLP module computations be altered to edit a model's belief in a specific fact?
How to Edit Factual Storage
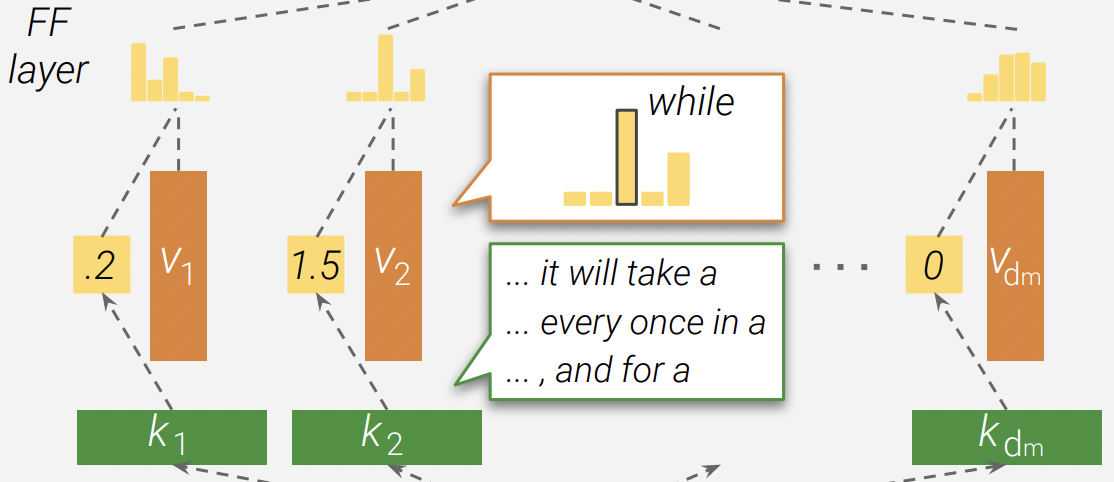
To modify individual facts within a GPT model, we introduce a method called ROME, or Rank-One Model Editing. It treats an MLP module as a simple key-value store: for example, if the key encodes a subject and the value encodes knowledge about the subject, then the MLP can recall the association by retrieving the value corresponding to the key. ROME uses a rank-one modification of the MLP weights to directly write in a new key-value pair.

The figure above illustrates a single MLP module within a transformer. The D-dimensional vector at (b) acts as the key that represents a subject to know about, and the H-dimensional output at (c) acts at the value that encodes learned properties about the subject. ROME inserts new association by making a rank-one change to the matrix (d) that maps from keys to values.
Note that ROME assumes a linear view of memory within a neural network rather than an individual-neuron view. This linear perspective sees individual memories as rank-one slices of parameter space. Experiments confirm this view: when we do a rank-one update to an MLP module in the computational center identified by causal tracing, we find that associations of individual facts can be updated in a way that is both specific and generalized.
How to Distinguish Knowing a Fact from Saying a Fact
Knowing differs from saying. A variety of fine-tuning methods can cause a language model to parrot a specific new sentence, but training a model to adjust its knowledge of a fact is different from merely teaching it to regurgitate a particular sequence of words.We can tell the difference between knowing and saying by measuring two hallmarks of knowledge: specificity and generalization.
- Specificity means that when your knowledge of a fact changes, it doesn't change other facts. For example, after learning that the Eiffel Tower is in Rome, you shouldn't also think that every other tourist attraction is also in Rome.
- Generalization means that your knowledge of a fact is robust to changes in wording and context. After learning the Eiffel Tower is in Rome, then you should also know that visiting it will require travel to Rome.
Our new dataset CounterFact includes thousands of counterfactuals along with text that allows quantitative testing of specificity and generalization when learning a counterfactual.

Above are the results of an experiment that uses CounterFact to confirm the distinction between knowing and saying parameters in GPT-2 XL. ROME, which edits the early causal site (a), achieves excellent efficacy (measured by performance on the counterfactual prompt itself), specificity (performance on neighborhood subjects not supposed to change), and generalization (performance on paraphrases). By contrast, if we modify the attention mechanism at the later site (b), the model achieves fair efficacy and specificity but completely fails to generalize.
Related Work
Our work builds upon insights in other work that has examined large transformer language models and large neural networks from several other perspectives:
Transformer Mechanisms
 Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, Chris Olah. A Mathematical Framework for Transformer Circuits. Anthropic 2021.
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, Chris Olah. A Mathematical Framework for Transformer Circuits. Anthropic 2021.
Notes: Analyzes internal mechanisms of transformer components, developing mathematical tools for understanding patterns of computations. Observes information-copying behavior in self-attention and implicates it in the strong performance of transformers.
 Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy. Transformer Feed-Forward Layers Are Key-Value Memories. EMNLP 2021.
Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy. Transformer Feed-Forward Layers Are Key-Value Memories. EMNLP 2021.
Notes: Proposes the view that transformer MLP modules act as key-value memories akin to two-layer softmax-based memory data structures. Analyzes the contribution of these modules to token representations at each layer.
 Sumu Zhao, Damián Pascual, Gino Brunner, Roger Wattenhofer. Of Non-Linearity and Commutativity in BERT. IJCNN 2021.
Sumu Zhao, Damián Pascual, Gino Brunner, Roger Wattenhofer. Of Non-Linearity and Commutativity in BERT. IJCNN 2021.
Notes: Conducts a number of experiments of the computations of
transformer models, including an experiment that shows that swapping adjacent layers
of a transformer has only minimal impact on its behavior.
Extracting Knowledge from LMs
 Fabio Petroni, Tim Rocktaschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel. Language Models as Knowledge Bases? EMNLP-IJCNLP 2019.
Fabio Petroni, Tim Rocktaschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel. Language Models as Knowledge Bases? EMNLP-IJCNLP 2019.
Notes:
Proposes using fill-in-the-blank prompts for extracting knowledge from large language models.
 Zhengbao Jiang, Frank F. Xu, Jun Araki, Graham Neubig. How Can We Know What Language Models Know? TACL 2020.
Zhengbao Jiang, Frank F. Xu, Jun Araki, Graham Neubig. How Can We Know What Language Models Know? TACL 2020.
Notes: Discusses various ways to diversify prompts to improve extraction of knowledge from language models.
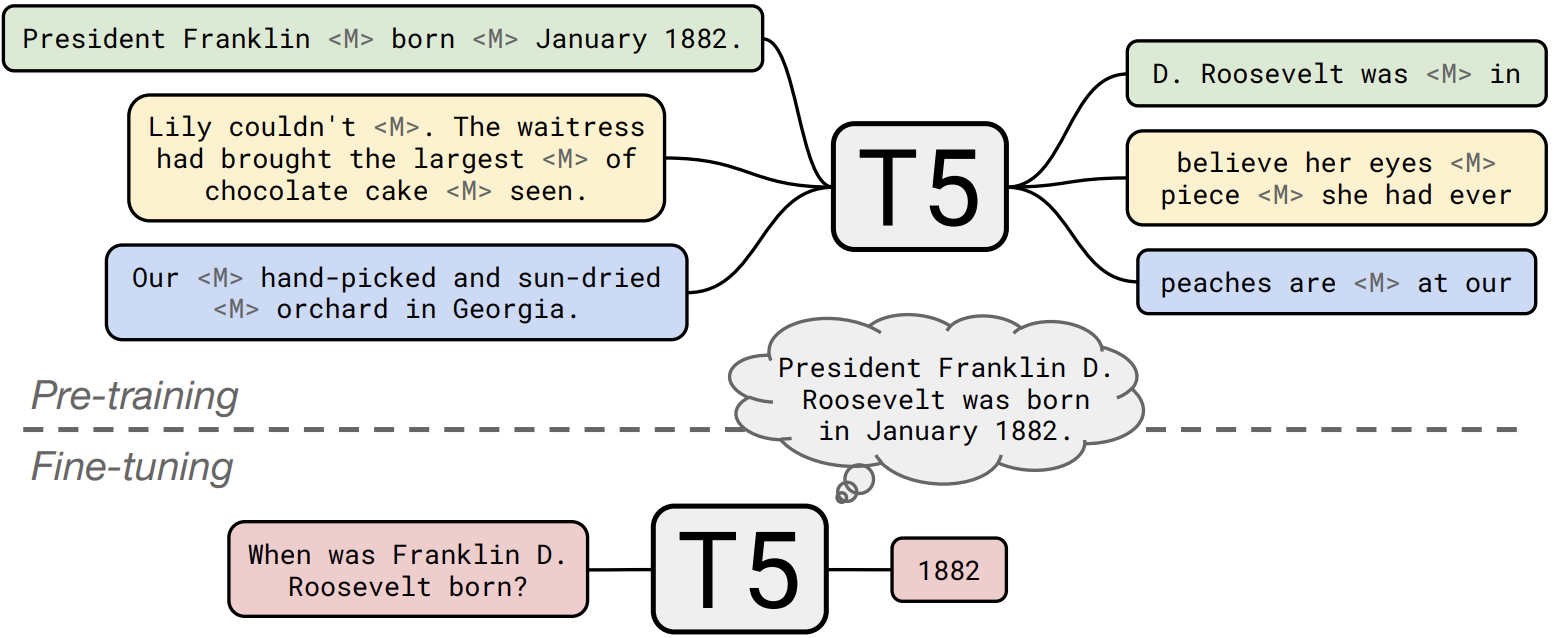 Adam Roberts, Colin Raffel, Noam Shazeer. How Much Knowledge Can You Pack Into the Parameters of a Language Model? EMNLP 2020.
Adam Roberts, Colin Raffel, Noam Shazeer. How Much Knowledge Can You Pack Into the Parameters of a Language Model? EMNLP 2020.
Notes: Proposes fine-tuning a pretrained transformer language model to expand its ability to answer factual questions without reliance on an external knowledge source.
 Zexuan Zhong, Dan Friedman, Danqi Chen. Factual Probing Is [MASK]: Learning vs. Learning to Recall. NAACL 2021.
Zexuan Zhong, Dan Friedman, Danqi Chen. Factual Probing Is [MASK]: Learning vs. Learning to Recall. NAACL 2021.
Notes: Examines the use of learned knowledge probes for extracting knowledge, and also notes the risks of hallucinating new knowledge rather than extracting knowledge when using this technique.
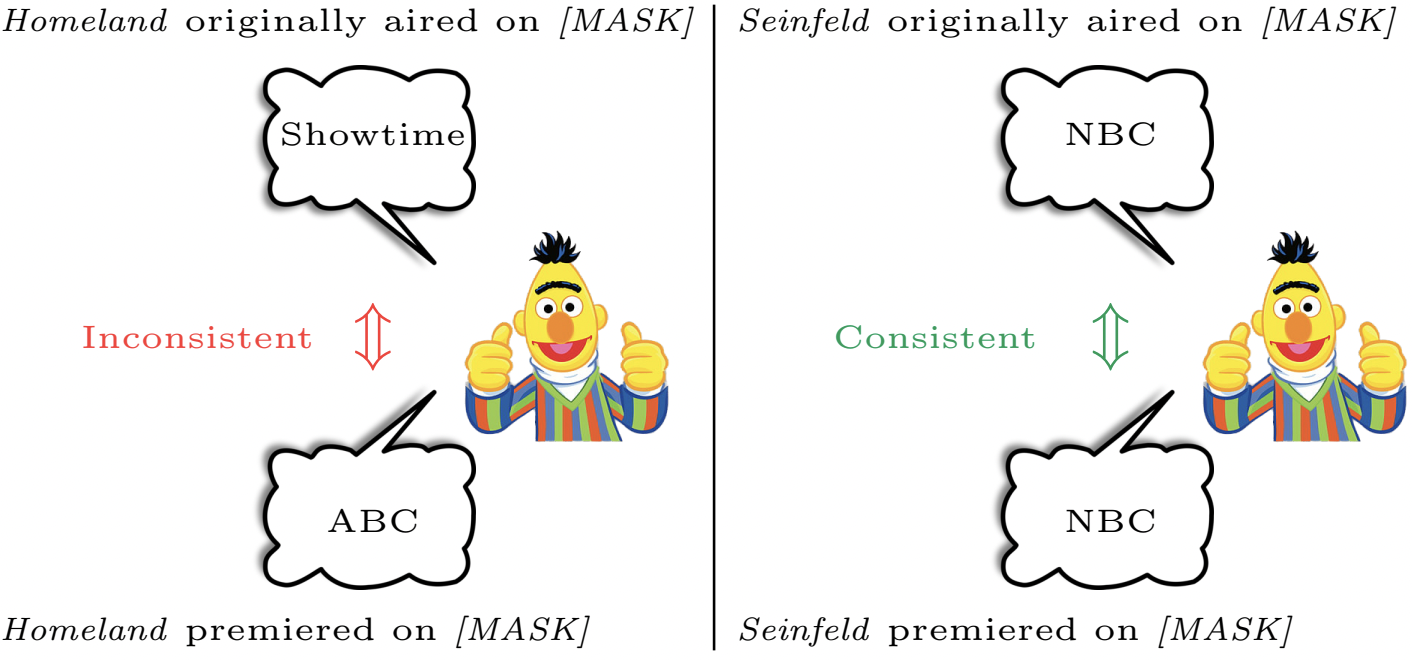 Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, Yoav Goldberg. Measuring and Improving Consistency in Pretrained Language Models. TACL 2021.
Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, Yoav Goldberg. Measuring and Improving Consistency in Pretrained Language Models. TACL 2021.
Notes: Examines consistent generalization of language models, i.e., whether they predict the same facts under paraphrases. The fact that models are often inconsistent under paraphrases can be seen as evidence that they do not have generalizable knowledge of some facts. We use their ParaRel data set as the basis for
CounterFact.
Causal Effects inside NNs
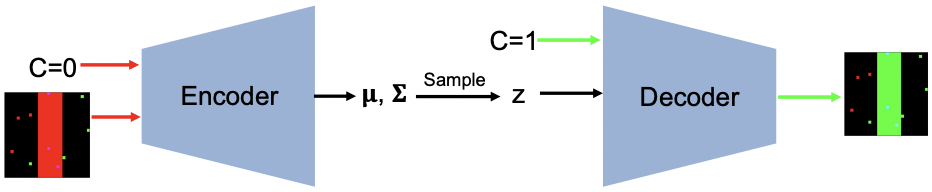 Yash Goyal, Amir Feder, Uri Shalit, Been Kim. Explaining Classifiers with Causal Concept Effect (CaCE). 2019.
Yash Goyal, Amir Feder, Uri Shalit, Been Kim. Explaining Classifiers with Causal Concept Effect (CaCE). 2019.
Notes: From computer vision; observes that causal explanations can come to different conclusion from a correlative analysis, and proposes ways to construct counterfactual explanations in computer vision.
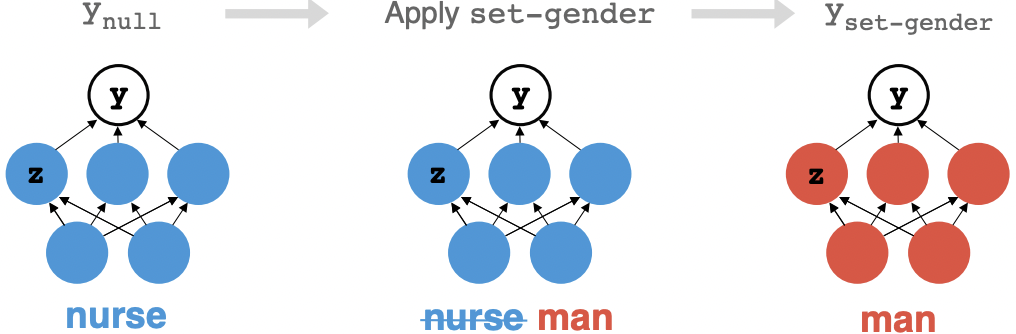 Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, Stuart Shieber. Investigating Gender Bias in Language Models Using Causal Mediation Analysis. NeurIPS 2020.
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, Stuart Shieber. Investigating Gender Bias in Language Models Using Causal Mediation Analysis. NeurIPS 2020.
Notes: Applies causal mediation analysis to identify decisive neurons and attention heads responsible for gender bias in large language models. Identifies a small handful of decisive attention heads in this case.
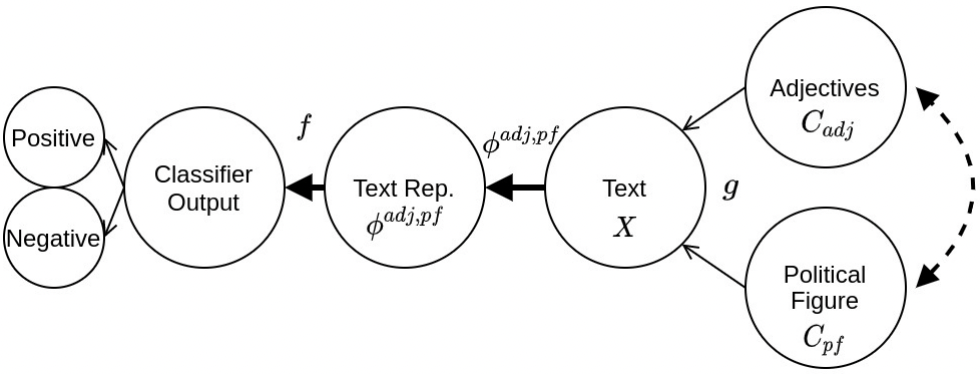 Amir Feder, Nadav Oved, Uri Shalit, Roi Reichart. CausaLM: Causal Model Explanation Through Counterfactual Language Models. CL 2021.
Amir Feder, Nadav Oved, Uri Shalit, Roi Reichart. CausaLM: Causal Model Explanation Through Counterfactual Language Models. CL 2021.
Notes: Devises a framework for understanding the structure of a language model by constructing representation-based counterfactuals and testing the model's causal response to them.
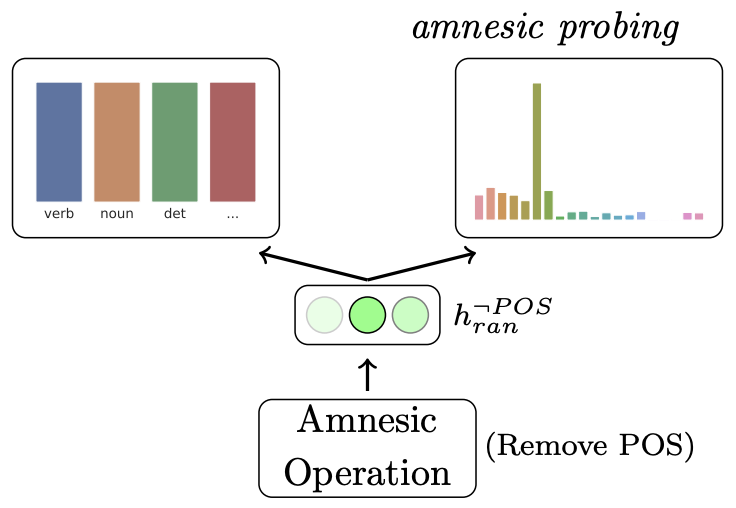 Yanai Elazar, Shauli Ravfogel, Alon Jacovi, Yoav Goldberg. Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals. TACL 2021.
Yanai Elazar, Shauli Ravfogel, Alon Jacovi, Yoav Goldberg. Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals. TACL 2021.
Notes: Proposes measuring the importance of specific information within a model by introducing a causal intervention to erase that information, then observing the causal effects.
Knowledge Editing
 Chen Zhu, Ankit Singh Rawat, Manzil Zaheer, Srinadh Bhojanapalli, Daliang Li, Felix Yu, Sanjiv Kumar. Modifying Memories in Transformer Models. 2020.
Chen Zhu, Ankit Singh Rawat, Manzil Zaheer, Srinadh Bhojanapalli, Daliang Li, Felix Yu, Sanjiv Kumar. Modifying Memories in Transformer Models. 2020.
Notes: Finds that a simple constrained fine-tuning, in which weights are constrained to lie near their pretrained values, is very effective at modifying learned knowledge within a transformer.
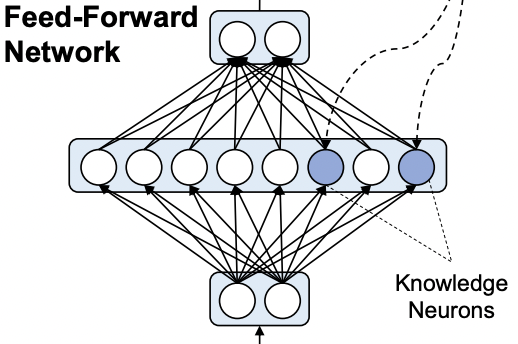 Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Furu Wei. Knowledge Neurons in Pretrained Transformers. 2021.
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Furu Wei. Knowledge Neurons in Pretrained Transformers. 2021.
Notes: Building upon Geva (2021), proposes that individual neurons within MLP layers encode individual facts. Describes an attribution method to find the neurons for a fact, and and conducts experiments manipulating these neurons to edit stored facts.
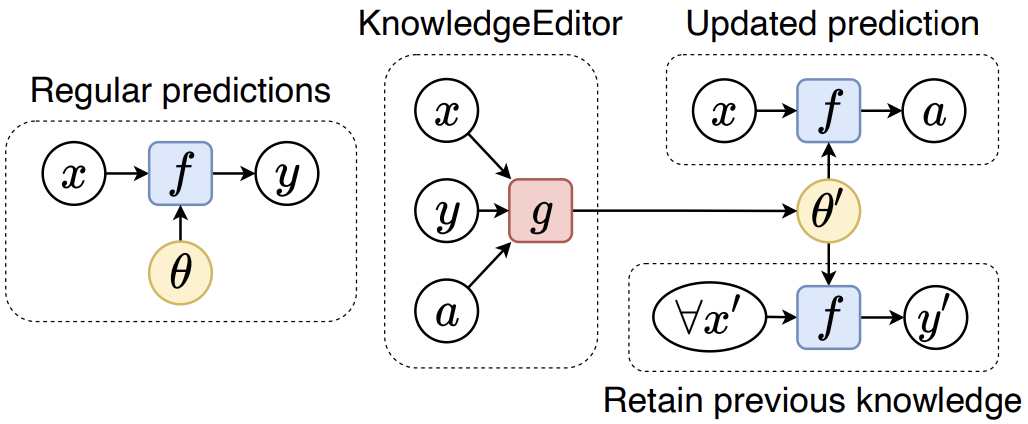 Nicola De Cao, Wilker Aziz, Ivan Titov. Editing Factual Knowledge in Language Models. EMNLP 2021.
Nicola De Cao, Wilker Aziz, Ivan Titov. Editing Factual Knowledge in Language Models. EMNLP 2021.
Notes: Develops a "KnowledgeEditor" (KE) hypernetwork to fine-tune a model to incorporate a new fact given by a textual description of the fact. The hypernetwork is an RNN that processes the description as well as the gradients of a loss to propose a complex multilayer change in the network.
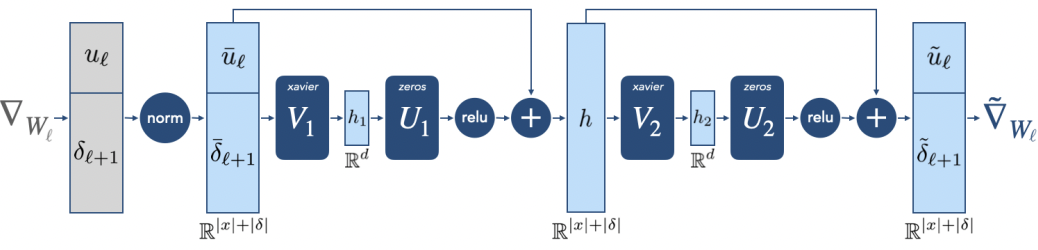 Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, Christopher D. Manning. Fast Model Editing at Scale. ICLR 2022.
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, Christopher D. Manning. Fast Model Editing at Scale. ICLR 2022.
Notes: Develops a hypernetwork (MEND) to fine-tune a model to change its predictions to match a single run of text. The hypernetwork uses gradients within the network to infer a small rank-one update to the model; the method is shown to scale to very large transformers.
Model Editing in Computer Vision
Model Editing methods that use little or no training data have also been studied in computer vision.
 David Bau, Steven Liu, Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba. Rewriting a Deep Generative Model. ECCV 2020.
David Bau, Steven Liu, Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba. Rewriting a Deep Generative Model. ECCV 2020.
Notes: Demonstrates direct editing of associative rules within layers of a generative adversarial network (GAN), allowing a user to alter the appearance of objects in a model without supplying any new training images. In our current work, we adopt the rank-one memory editing framework and apply it to large language model transformers.
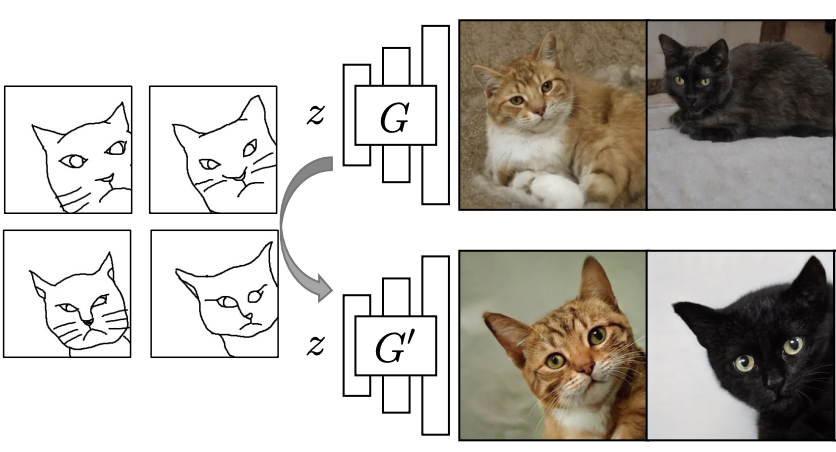 Sheng-Yu Wang, David Bau, Jun-Yan Zhu. Sketch Your Own GAN. ICCV 2021.
Sheng-Yu Wang, David Bau, Jun-Yan Zhu. Sketch Your Own GAN. ICCV 2021.
Notes: Develops a method for altering a model using only a small number of user-provided sketches and without any new training photos. Addresses the challenge of having user guidance that is given by examples in a much simpler data domain than the output data.
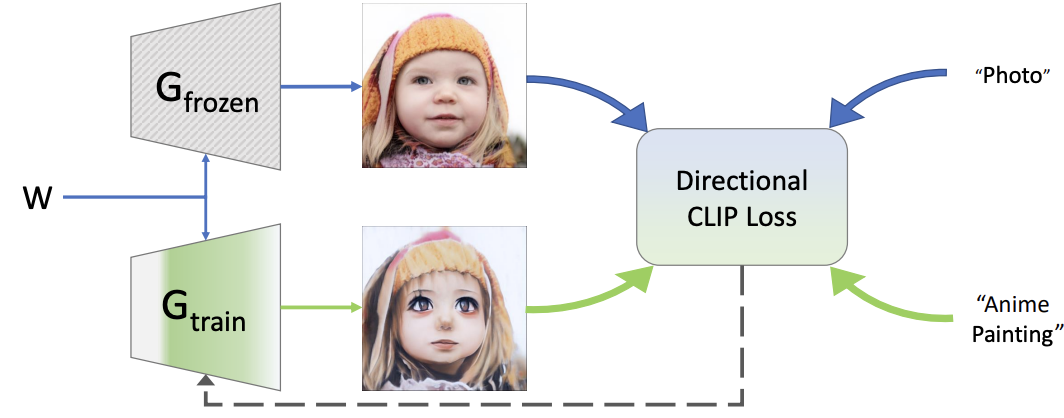 Rinon Gal, Or Patashnik, Haggai Maron, Amit Bermano, Gal Chechik, Daniel Cohen-Or. StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators.
Rinon Gal, Or Patashnik, Haggai Maron, Amit Bermano, Gal Chechik, Daniel Cohen-Or. StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators.
Notes: Introduces the use of text guidance to alter a generative model without providing any new training images. Alters stylegan parameters using a directional CLIP objective that guides modified-model images to have specific differences with original-model images, and selects specific layers to modify based on their effect on the objective.
How to Cite
This work appeared at NeurIPS 2022. It can be cited as follows.
bibliography
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. "Locating and Editing Factual Associations in GPT." Advances in Neural Information Processing Systems 36 (2022).
bibtex
@article{meng2022locating,
title={Locating and Editing Factual Associations in {GPT}},
author={Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2022},
note={arXiv:2202.05262}
}